MapReduce中的”group by”操作用于將具有相同鍵值的記錄分組在一起。在Map階段,框架會根據定義的鍵對輸出結果進行排序和分組;到了Reduce階段,每個組的數據會被傳遞給對應的Reduce函數進行處理。這在數據分析中常用于聚合計算,如計數、求和等。
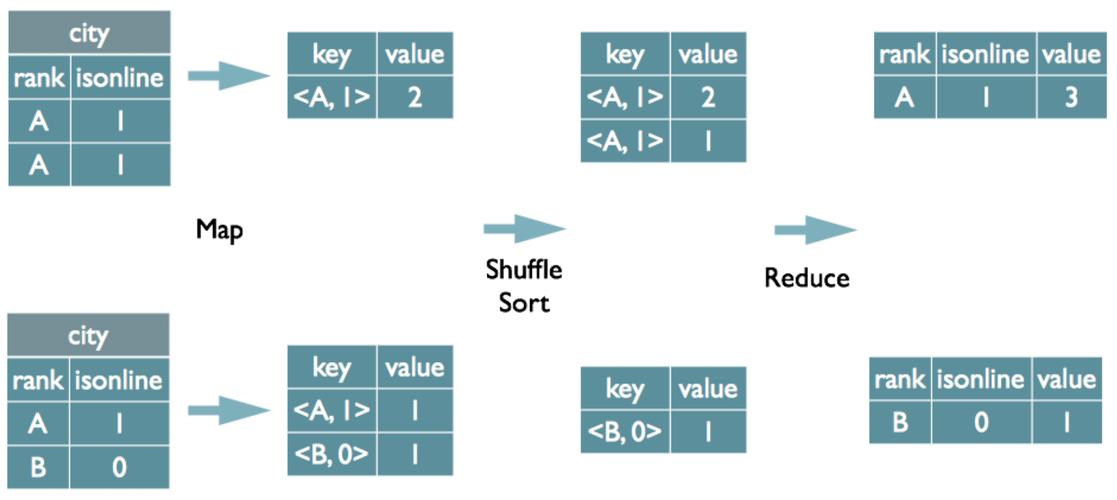

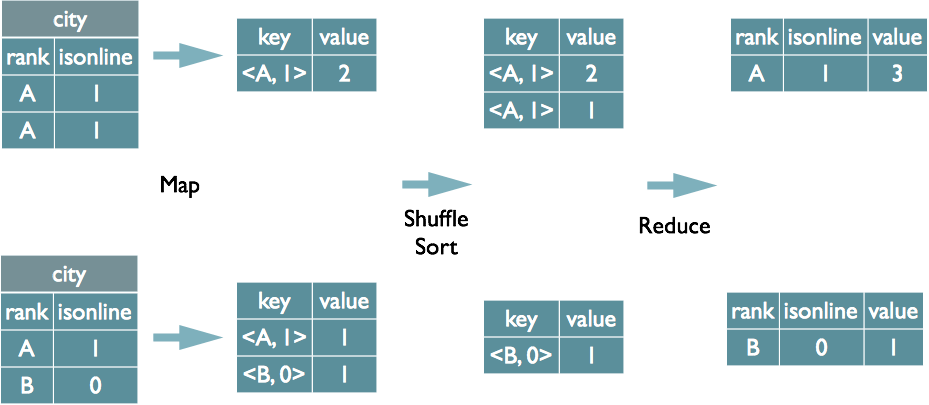
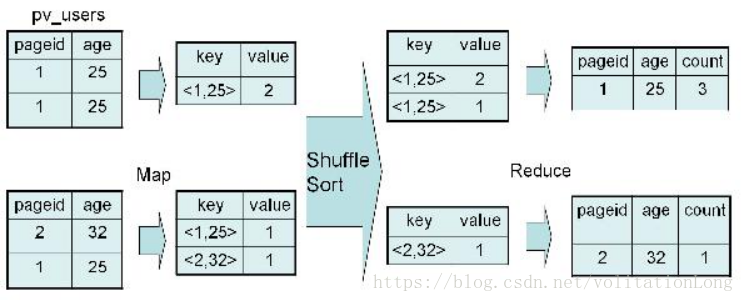
MapReduce是一種編程模型,用于處理和生成大數據集的并行算法,它由兩個主要步驟組成:Map(映射)和Reduce(歸約),在MapReduce中,數據被分成多個獨立的塊,每個塊在不同的節點上進行處理。
"group by_GROUP" 是一個常見的需求,通常用于對數據進行分組并計算每個組的聚合值,下面是一個使用MapReduce實現"group by_GROUP"功能的示例:
Map階段
在Map階段,輸入數據被分割成多個鍵值對(keyvalue pairs),對于每個鍵值對,我們將其傳遞給一個Map函數,該函數將鍵值對轉換為中間鍵值對,在這個例子中,我們將根據某個屬性(用戶ID)對數據進行分組,并將該屬性作為中間鍵。
def map(key, value):
# key: 輸入數據的鍵
# value: 輸入數據的值
# 假設value是一個包含用戶ID和其他信息的元組
user_id = value[0] # 提取用戶ID作為中間鍵
# 輸出中間鍵值對,其中鍵是用戶ID,值是原始數據
emit(user_id, value)
Shuffle階段
Shuffle階段負責將Map階段的輸出按照中間鍵(這里是用戶ID)進行排序和分組,這樣,所有具有相同用戶ID的數據都會被發送到同一個Reduce任務。
Reduce階段
在Reduce階段,每個Reduce任務接收到一個中間鍵及其對應的所有值的列表,Reduce函數將這些值組合成一個單一的輸出結果,在這個例子中,我們將計算每個用戶組的總和或其他聚合值。
def reduce(key, values):
# key: 中間鍵,即用戶ID
# values: 與該用戶ID關聯的所有值的列表
# 假設我們要計算每個用戶組的總和
total_sum = sum([value[1] for value in values]) # 假設value[1]是要累加的值
# 輸出最終結果,其中鍵是用戶ID,值是總和
emit(key, total_sum)
示例代碼
以下是一個簡單的Python代碼示例,演示了如何使用MapReduce實現"group by_GROUP"功能:
from mrjob.job import MRJob
from mrjob.step import MRStep
class GroupByGroupJob(MRJob):
def steps(self):
return [
MRStep(mapper=self.mapper, reducer=self.reducer)
]
def mapper(self, _, line):
user_id, value = line.split() # 假設輸入數據是空格分隔的用戶ID和值
yield user_id, float(value) # 輸出中間鍵值對
def reducer(self, key, values):
total_sum = sum(values) # 計算每個用戶組的總和
yield key, total_sum # 輸出最終結果
if __name__ == '__main__':
GroupByGroupJob.run()
這個示例代碼使用了mrjob庫來實現MapReduce作業,在實際環境中,您可能需要根據您的數據源和目標選擇合適的Hadoop或Spark等分布式計算框架來運行MapReduce任務。
聲明:所有內容來自互聯網搜索結果,不保證100%準確性,僅供參考。如若本站內容侵犯了原著者的合法權益,可聯系我們進行處理。